在本系列的第一篇文章中, 我们探讨了HTTP的基本概念。有了(前面的)基础, 我们就可以开始HTTP结构体系的学习。 HTTP协议不仅仅只是用来发送和接收数据的。
实际上, HTTP协议本身是不能作为应用程序协议工作的, 但是因为它的基础结构是由硬件和软件组成, 软硬件协同工作提供了不同的服务, 这才能在万维网上实现有效的通信。
本文是HTTP系列文章的第二部分。
文章概要:
- Web服务器(Web Severs)
- 代理服务器(Proxy Severs)
- 缓存(Caching)
- 网关(Gateways), 隧道(Tunnels), 中继代理(Relays)
- 网络爬虫(Web Crawlers)
这些都是我们网络生活中不可分割的一部分, 接下来, 你可以(通过本文)全面地了解它们的用途及其工作形式。接下来学习的内容可以帮你把第一篇文章中的(知识)点串起来, 这样, 你就可以熟悉HTTP通信过程。
那么, 让我们现在就开始学习吧!
Web服务器
正如第一篇文章所提到的, Web服务器的主要功能是存储资源并在接收请求后(按照请求)处理资源。通过Web客户端(又称为Web浏览器)用户可访问Web服务器, 并返回获取请求的资源或更改(资源的)现有的状态。访问Web服务器的操作, 通过网络爬虫, 也可以实现自动化, 相关内容我们会在文章后面进行深入的了解。
你所知道的最流行的服务器, 不外乎是Apache的HTTP 服务器、Nginx、
IIS、Glassfish…
Web服务器可分为(使用)单种简单易用的软件或(使用)多种复杂的软件的服务器。 现代的Web服务器能够执行许多不同的任务, 其基本功能为:
- 建立连接 —— 接受或关闭客户端连接
- 接收请求 —— 读取HTTP请求报文
- 处理请求 —— 解析请求报文并执行(相应请求)
- 访问资源 —— 访问请求报文中(请求的)资源
- 构造响应 —— 创建HTTP响应报文
- 发送响应 —— 向客户端返回响应报文
- 事务日志 —— 在日志文件中记录已完成的事务
我将Web服务器基本(工作)流程分为不同的阶段, 所列出的阶段是Web服务器(工作)流程的一个极其简化的版本。
阶段 1:建立连接
当Web客户端要访问Web服务器时, 客户端必须要重新打开一个TCP连接。与此同时, Web服务器在另一边向客户端确认IP地址。然后, 由服务器决定是否与该客户端建立TCP连接。
如果服务器接受连接, 它会将客户端的IP地址添加到现有连接的列表中, 并监视该连接上的数据。
如果客户端未被授权或是黑名单中的(视为恶意的), 服务器可以关闭TCP连接。
服务器还可以使用”反向 DNS(Domain Name System, 域名服务器)”来识别客户端的主机名。客户端的主机名有利于事务日志的记录, 但主机名的查找需要时间, 所以会造成记录事务的速度减慢。
阶段 2:接收/处理请求
分析接收的请求时, Web服务器会分析报文的请求行、首部字段和主体(如果有提供的话) 中的信息。需要注意的一点是, TCP连接可以随时暂停, 因此在这种情况下, 服务器必须将(已传送)数据临时存储起来, 直到服务器接收到剩余(未传输的)数据。
高端的Web服务器能够同时建立大量连接——包括同时与同一客户端有多个连接。因此, 典型Web页面可以向高端服务器请求大量不同的资源。
阶段 3:访问资源
Web 服务器通过多种方法映射和操作资源, (为Web客户端)提供资源。
映射资源最简单的方法, 就是根据请求(报文)中的URI在Web服务器的文件系统中查找所需的文件。通常, 资源都存放在服务器上一个被称为文件根目录(docroot)的特殊文件夹中。例如, Windows 服务器上的文件根目录就位于“F:\WebResources \”。假设有一个GET请求想要访问”/image/codemazeblog”上的文件, 服务器会将其转换为”F:\WebResources\images\codemazeblog.txt”, 并在响应报文中返回该文件。当一个Web 服务器承载多个网站时, 每个站点都会有其独立的的文件根目录。
如果 Web 服务器接收到的是对(文件)路径的请求, 而不是对文件的请求, 服务器可以用以下几种方式处理请求:返回错误消息; 替代返回路径或遍历路径, 返回默认索引文件;返回带有(所请求)内容的HTML文件。
服务器还可以将请求(报文)中的URI映射到动态资源上, 这些动态资源是由应用程序生成的。有一类服务器叫做应用程序服务器, 其功能就是管理动态资源, 它还能给Web服务器提供复杂的软件解决方案。
阶段 4:生成及发送响应
一旦服务器确定了需要所请求的资源, 它就会生成响应报文, 报文中包含状态码、响应首部字段, 若请求(报文)中需要的话还应有响应主体。
如果存在响应主体, 那么该响应报文通常包含Content-Length和Content-Type两个首部字段——Content-Length描述主体大小, Content-Type描述返回资源的MIME类型。
生成响应(报文)后, 服务器选择需要发送响应的客户端。对于非持久性(长期)连接, 服务器需要在发送整个响应消息后关闭连接。
阶段 5:记录事务
服务器在事务完成后将记录文件中的所有事务信息, 大部分的服务器都采用自定义的方式记录日志。
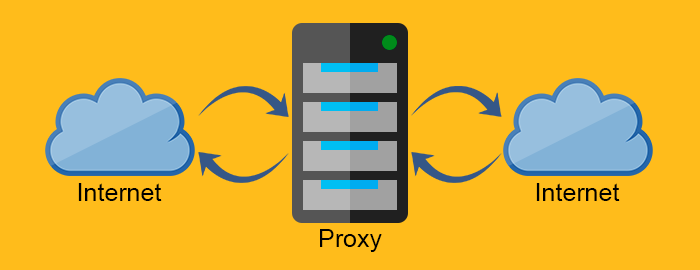
代理服务器
代理服务器 (代理) 是的中间服务器, 通常位于Web服务器和Web客户端之间, 因其性质, 代理服务器需要兼并Web客户端和Web服务器的功能。
不过, 为什么要用代理服务器呢?为什么不直接用Web客户端和Web服务器进行通信?这难道不是更加简单快速吗?
当然, (直接利用Web客户端和Web服务器)操作起来是很简单, 不过说到速度快, 那就未必了。接下来, 我们会了解原因的。
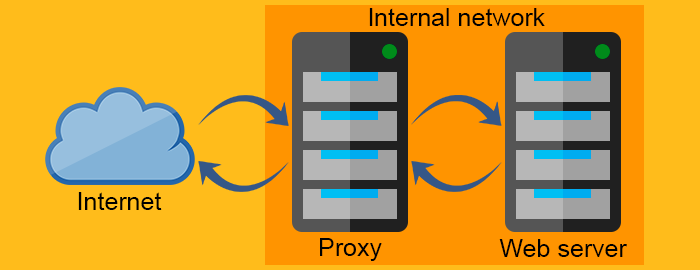
在解释什么是代理服务器之前, 我们先要搬开一块大石头, 那就是反向代理服务器(reverse proxy)的概念。 换句话来说就是知道 正向代理(forward proxy)和反向代理( reverse proxy)有什么区别。
正向代理负责向Web服务器请求资源, 并将资源返回到客户端。除此之外, 正向代理还能通过防火墙过滤请求或隐藏客户端信息来维护客户端的安全。而反向代理的工作方式(与正向代理)完全相反, 它通常位于防火墙之后来保护 Web 服务器。所有客户端已知其通信对象是实际的Web服务器, 但却了解反向代理背后的(Web服务器所处的)网络。
代理服务器
反向代理服务器
代理(服务器)非常有用并且应用十分广泛。接下来, 让我们来了解一下代理服务器的功能。
- 压缩(Compression) —— 就是简单地利用压缩内容的方式加快通信速度。
- 监控(Monitoring)和过滤(filtering) —— 用代理服务器(进行监控和过滤)不失为一个阻止小学生访问成人网站好方法。🙂
- 安全(Security) —— 代理(服务器)可以作为整个网络的一个独立的入口点, 它们能够检测恶意软件和对应用层协议设限。
- 匿名性(Anonymity) —— 代理可以修改请求(报文)以提高匿名性, 它可以从请求中剥离敏感信息, 只留下重要的东西。尽管向服务器发送较少的信息会降低用户体验,
但是有时侯, 匿名性(比用户体验)更重要。 - 访问控制(Access control) —— 若要实现对多个服务器的访问控制, 集中管理单个代理服务器即可。
- 缓存(Caching) —— 使用代理服务器缓存常用的内容, 会大大降低加载速度。注:这里的加载速度按照我自己的理解, 应该是如果存在缓存的话,
服务器需要先去加载缓存中的内容, 这会降低加载的速度 - 负载均衡(Load balancing) —— 如果服务达到性能的临界点, 你可以使用负载均衡器——负载均衡器是一种可均衡分配路由通信量的代理, 可避免在服务性能达到临界点时导致单个服务器超负荷——分配在资源或Web服务器中的负载。
- 转码(Transcoding) —— 代理服务器有修改报文主体的功能。
综上所述, 代理(服务器)有功能多样且可灵活使用的特点。
缓存
Web 缓存(系统)是一种可以自动复制请求报文数据并将其保存到本地存储中的设备。
Web缓存的优点:
- 减少通信量
- 消除网络瓶颈
- 防止服务器草符合
- 降低长距离造成的响应延迟
因此, 可以直白地说, Web缓存改善了用户体验和服务器性能。当然, 还有可能省了很多钱。
命中率的范围由0至1, 其中0表示缓冲提供所请求的0%资源 ,而1表示缓冲提供所请求的100%资源。命中率最理想的状态当然是达到100%, 但是, 实际命中率通常只能接近40%。
下面是基本的Web缓存的工作流程: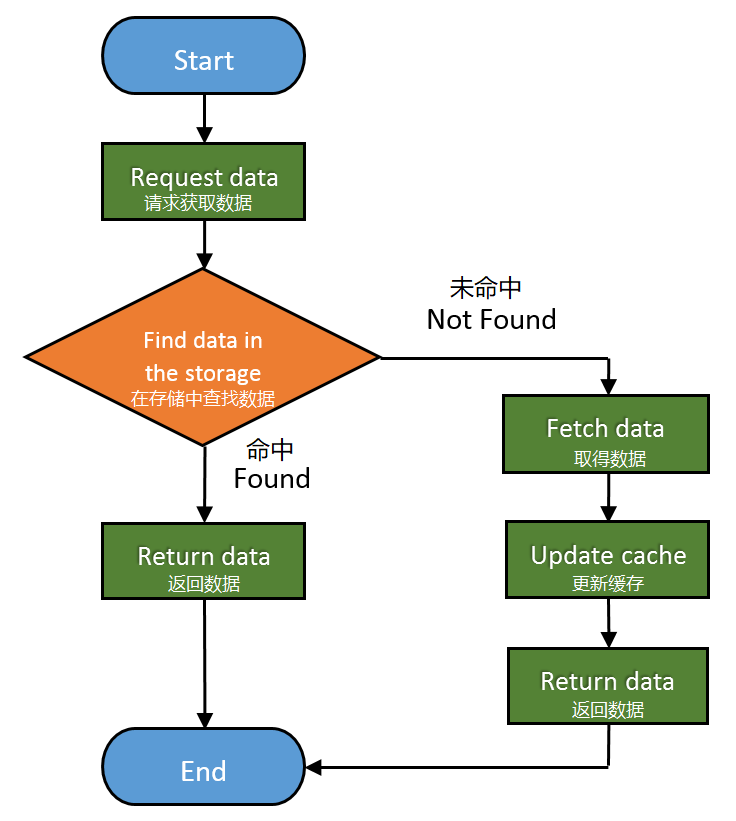
网关、隧道、中继代理
随着HTTP(越来越)成熟, 不同的HTTP协议使用方法不断涌现出来。这就促使, HTTP——连接不同应用程序和协议的框架——变得非常有用。
接下来, 就让我们来看看HTTP是怎么做到如此有用的。
网关
网关是一种(网络)硬件,它能够通过抽象方法使 HTTP协议与不同协议和不同应用程序进行通信, 从而获得资源。网关也被称为协议转换器, 由于(具有)多个协议的应用, 所以它比路由器或交换机复杂得多。
下面是网关利用转换协议工作的实例:使用网关发送HTTP请求可以接收到FTP(File Transfer Protocol, 文件传输协议)文件; 使用客户端加速安全网关可以接收到SSL(Secure Sockets Layer, 安全套接层)加密后转换成HTTP协议的报文; 使用服务器端安全网关可以将HTTP报文转换成更安全的HTTPs报文(Hypertext Transfer Protocol Secure, 超文本传输安全协议);
隧道
隧道(协议)是利用CONNECT请求方法实现的, 该协议能够通过HTTP协议发送非HTTP的数据。CONNECT是一个(客户端)要求代理连接目标服务器的请求方法, 并且在客户端和服务器之间中转数据。
注:上面这句话简单理解就是, 隧道协议不用HTTP解析数据, 对数据不做任何处理, 只将数据直接中转给目标服务器。
CONNECT请求:1
2
3CONNECT api.github.com:443 HTTP/1.0
User-Agent: Chrome/58.0.3029.110
Accept: text/html,application/xhtml+xml,application/xml
CONNECT响应:1
2HTTP/1.0 200 Connection Established
Proxy-agent: Netscape-Proxy/1.1
与常规的HTTP响应(报文)不同, CONNECT响应不需要特别说明Content-Type字段。
一旦(隧道)建立了连接,客户端和服务器就可以直接进行通信。
中继代理
中继(服务器)在HTTP世界中充当着坏人的角色, 他们不受HTTP的律法束缚。实际上, 中继(服务器)是代理的简化版本, 只要它们能够建立连接——仅需请求报文中极少信息量——那么就可以中转所有接收到的信息。
中继存在的唯一的理由就是, (在某些情况下)需要一个尽可能少惹麻烦的代理。不过, 使用中继也可能带来麻烦。因此中继是应用在特定场景下, 所以在添加中继(服务器)之前, 一定要先考虑添加之后的损益比。
网络爬虫

当然, 通常都称呼它为网络蜘蛛(spiders), 它是一种网络机器人, 用于自动浏览万维网和编纂网络索引。因此,对于搜索引擎和大部分来说, 网络爬虫是必不可少的工具。
网络爬虫是一个全自动化的软件, 不需要人机交互。网络爬虫的复杂度差异会很大, 一些网络爬虫就非常复杂(比如搜索引擎用的爬虫)。
网络爬虫会消耗所访问的网站的资源。因此, 公开的网站有一个机制去告知爬虫:网站哪些内容可被抓取, 或禁止爬虫抓取任何数据。你可以通过robots.txtRobots Exclusion Protocol, 漫游器排除协议)去实现这个机制。
毫无疑问, robots.txt不能阻止那些不请自来的网络爬虫抓取网站, 因为它只是一个标准。也就是说, robots.txt只能防君子不能防小人。
下面是robots.txt书写方式的举例:1
2User-agent: *
Disallow: /
含义:禁止所有爬虫访问网站的任何部分。1
2
3
4User-agent: *
Disallow: /somefolder/
Disallow: /notinterestingstuff/
Disallow: /directory/file.html
含义:仅禁止访问两个特定的目录和文件。1
2User-agent: Googlebot
Disallow: /private/
含义:在特定情况下, 禁止指定的爬虫访问。
不过, 鉴于万维网的庞大, 即使是有史以来最强大的爬虫, 也无法抓取整个网络的资源并编纂整个网络的索引。这就是爬虫使用选择策略(selection policy)抓取关联性最大的部分的原因。此外, 万维网经常发生动态变化, 因此爬虫必须用重新访问策略(freshness policy )去计算它们是否能再次访问网站。并且, 爬虫轻松覆盖整个服务器的资源时, 会采取发送过于快速和繁多的请求的举措, 因此爬虫会采取平衡礼貌策略(politeness policy)避免造成服务器不能正常使用。已知的大部分爬虫, 以低至20秒高至3-4分钟的时间间隔对服务器进行轮询, 避免使服务器上超载。
注:重新访问策略其实就是为了避免资源过期, 爬虫进行确认的一个机制。
你可能听说过神秘又邪恶的深网或暗网。但是, 深网(暗网)只是网络的一部分, 搜索引擎为了将(其中的)信息藏起来故意不把它们编入索引。
总结
这个链接是HTTP系列的目录及简介。相信你现在脑海中对HTTP工作流程已经有了更加清晰的概念, 学到了比(原本的)请求、响应、状态码更多的知识正是不同的软硬件结合的整体架构, 才让作为应用层协议的HTTP能够发挥出它的潜能。
我在这篇文章谈到的每个概念都很庞大, 大到足以用一篇文章甚至一本书来细细讲述。不过, 我只是想大概介绍一下概念, 这样你们就知道这些概念是如何搭配使用的, 方便你们之后查找相关内容。
如果在阅读的过程中, 你发现有些内容解释得过于简短和不清晰并且没有看过我之前的文章, 你可以阅读这篇文章的第一部分和HTTP指南, 在这两篇文章中都有关于HTTP基本概念的概述。
感谢你阅读本文, 敬请关注HTTP系列的第三部分, 我在这篇文章中讲述了服务器是如何识别客户端的。
